We need more control over AI’s influence on our stories
As predicted, AI’s impact on the storytelling industry was significant in 2023, and it was just getting started. But our collective control over the impact that AI is having on reshaping our industry while unlocking both major opportunities and risks is not nearly keeping up. It is essential for entertainment industry stakeholders, and those who protect consumers, to better understand and address the potential of this innovation to impact the stories we create, and how the narrative of AI’s development unfolds for our industry.

AI Content Reflects Probable Outputs of Its Training Data
AI can help to create content based on the generative tool’s calculation on what is probably the best outcome. Avi Bar-Zeev, now President of the XR Guild and RealityPrime consultancy, has pioneered technologies for storytelling and enterprise uses for over three decades, with milestones including co-founding Keyhole (Google Earth), co-inventing the Hololens AR headset, crafting Second Life’s 3D worlds and leading Apple's Vision Pro Experience Prototyping team. Generative AI, shares Bar-Zeev, “can become a superpower to people who can’t draw or write well, but it’s not as good as the professionals yet. The main reason for that is that it still can’t tell the difference between good and bad content, true vs. false, or resonating with vs. disorienting the audience. It can only tell us what is the most likely response, based on what it’s ingested… It's even more critical to everyone’s survival that AI be based in truth. Allowing pervasive disinformation to accumulate inside these models is something that harms even more people in much subtler ways.”
Additionally, generating what AI perceives as the most probable outcomes can perpetuate bias, stereotypes and inaccuracies in content, impacting story content and the negative impact it may have on audience perspective. Creators should invest time in ensuring that inputs they receive from AI are vetted for accuracy and bias so as not to perpetuate it and to tell better, different stories.
Rights to Our Creative Output and Likeness
“Right now the main battlefield is on the subset of IP known as copyright.” says Sam Posner, Entertainment Lawyer at Platform Law. “There will probably come a day when legal battles are fought over trademarks, patents and other areas of IP, but right now, the volume and nature of work that AI needs to build its brain orbits around copyright. In order to qualify for copyright protection in most countries, the work needs to be fixed in some recorded media (written down, emailed, filmed, painted, photographed, etc.) and must be original, otherwise it will infringe the copyright of another author.”
It is also important to understand what is not copyrightable: “There is a known sandbox of things like titles of works (unless trademarked), factual data (e.g. baseball statistics, however the visual presentation of such data could be copyrightable, but the data itself no), very short and common phrases, and ideas that aren’t fixed/recorded. People often ask, “how can I protect my idea?” The most legally proactive way, right now, is to write it out in as much detail as possible (or in whatever media apply) and register copyright at the Intellectual Property office.”
Posner cautions, however, that copywriting may not be foolproof against deep-pocketed venture backed organizations. They can also try to deter training of their content by making it “practically difficult or frustrating… by adding watermarks for example" or “similar methods depending on the nature of the work” although AI can power a workaround for this.
Are there ways for creators to try to identify if their IP has been used in training? “The answer, as many fear, is “probably not”” says Posner, “unless something in AI output reveals its knowledge of a certain work. Eventually I expect AI will know how to evade this kind of liability. Theoretically, if one were to sue an AI firm for copyright infringement, the training material would be “discoverable” and the defendant AI firm would need to disclose it to the plaintiff – however, practically, that would be a very difficult, expensive and frustrating approach for a plaintiff to have to take to answer this very basic question.”
Investing in copyright protection is not always possible for creators. Defending copyrighted materials is becoming even more resource intensive, especially in situations where a creator or a small studio is defending their copyrighted materials against a larger AI entity. Canadian creators and their IP need help solving this. Support from organizations granting or investing in Canadian IP could help identify ways to support this protection of IP and their owners’ business.
AI was an essential topic during the SAG-AFTRA and Writers Guild of America negotiations, and it should be the case for all similar organizations representing talent. In this case it was related to both creative output and talent likeness. “I think it was somewhat helpful to go through these sorts of pushback vs. the executives who may very well try to replace people with AI to save money.” expressed Bar-Zeev.
“What matters is not the bits or the algorithm but how people perceive the end results”
Avi Bar-Zeev
“If Picture A and Picture B look nearly identical and A has a registered copyright, then B is likely infringing.” says Bar-Zeev. The New York Times case is a good example for us to understand. “If OpenAI’s outputs are truly transformative (and allowed under “Fair Use”), then people should be using the content for other purposes. If ChatGPT can give us the same article the NYT published, then we don’t need to pay NYT for basically the same stuff. If OpenAI is providing a service that the NYT doesn’t or can’t, then it may be transformative enough to survive as-is.

Protecting Audiences
Actors are not the only ones that need to protect their likeness. “If actors can establish that they get paid when their likeness is used, does that help everyone have sovereignty over their own personal data?” asks Bar-Zeev. There is an opportunity “for government to step in and say not just actors but everyone owns their personal data. Companies may license it from us, if we agree, but it’s not a coercive click-wrap agreement like it is today” he says, referring to platforms such as consumer AI tools and social media that have agreements like this.
Hyper-personalization of content powered by AI is both an opportunity and risk to audiences. AI can be trained to deceive audiences.“The biggest risk” says Bar-Zeev, is that much cheaper human-like content can trick or fool people into believing it is genuine, truthful, and working in their interests vs. secretly against them. It will become very easy for ad-tech to subtly modify most AI-backed content to better monetize the audience and any gleaned personal data. The way we interact with content will become even more important for such companies to collect and use against us. And by using that beloved content offensively, companies can better penetrate our lives. For example, it’s easy to imagine our friends and families being used to sell products they aren’t even aware of.”
AI is also powering content that comes to life around audiences’ personal spaces, connecting digital content with physical places, objects and even the user (such as through eye or hand tracking) through mixed reality. This unlocks new storytelling opportunities as well as the need to protect consumer data even more.
Selection of AI Tools, Distribution Platforms
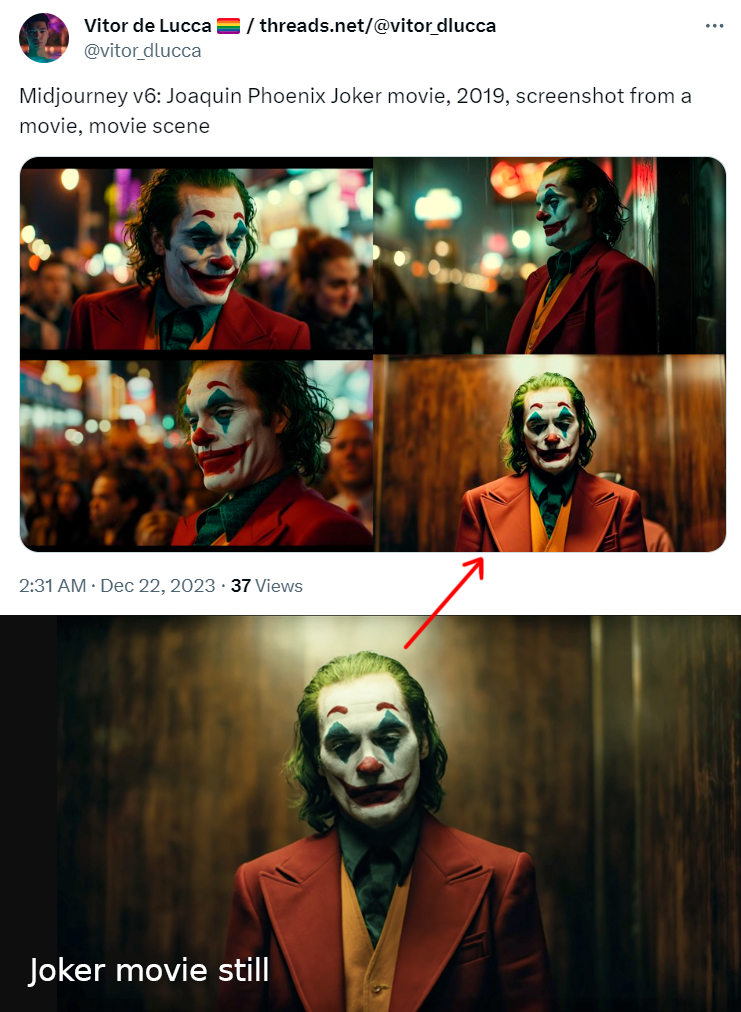
Bar-Zeev encourages generative AI companies to figure out a “provenance, credit and pay” solution. However the question is: are companies going to do this? OpenAI stated in court filings that "it would be impossible to train today's leading AI models without using copyrighted materials". When asked if his company sought consent to use works from living artists or still under copyright, Midjourney Founder David Holz replied with a “No.”
“All collaborators should have a contract in place between them setting out their own respective ownership and governance with respect to their work, but to the extent that AI is involved, the “terms of use” of the AI platform will contractually govern the use of output generated by AI” cautions Posner. “Ownership will be the most important issue, and the AI work will either be owned by the human collaborators, the AI platform, or jointly owned by both.”
“Human collaborators should also consider whether AI can effectively generate work that is not infringing on third party IP.” suggests Posner. “This is already true of non-AI work generation, but AI doesn’t improve upon this existing liability. In order to have certainty, the AI would need to know the registers of all IP worldwide; however, copyright for example, doesn’t need to be registered to be valid and enforceable. So – unless the law changes to require registration – there will always be some risk that somebody had an idea before AI (and they can prove it), and AI hasn’t obtained what we would call a “clearance” (i.e. a license) to use that work. Perhaps more to the issue, humans should consider whether AI understands what kinds of output would be legally defensible if and when the AI uses protected (copyrighted or trademarked) works to generate output.”



